- The Technology Brother
- Posts
- Is SORA what Ilya saw?

Back in November, amidst the chaos and confusion of Sam Altman’s ouster by the board of OpenAI and the disappearance of co-founder Ilya Sutskever afterwards, many of us began asking the same burning question: “What did Ilya see?” At first just a meme, the question quickly turned serious, with everyone wondering what sort of massive development or breakthrough might have shook Ilya so deeply. Well, maybe now we know.
Fresh off his request for seven trillion dollars to reshape the global semiconductor industry, Sam Altman and his team over at OpenAI delivered a brand-new model this past Thursday morning. And it’s simply mind-boggling. In a series of tweets, Sam and OpenAI unveiled Sora – their groundbreaking text-to-video generation model. Similar to the release of DALLE-3, Sam and others quickly began taking prompt requests from the public. Those generations, along with those on the official model page, are downright breathtaking.
Sora generates realistic, detailed, and incredibly creative videos up to a minute long from the simplest of text prompts, spitting out complex scenes with detailed characters, motion, and backgrounds. Already, it’s being released to red teamers and a select group of visual artists, designers, and filmmakers in order to test its capabilities. And those capabilities are mind-blowing. So what can Sora do? And how is it doing it? How has OpenAI developed arguably the most impressive AI since ChatGPT?
Let’s start by looking in depth at what Sora is capable of (hint: it’s much more useful than it may seem). Like other diffusion transformer models, Sora takes as input a text prompt from the user, such as “Historical footage of California during the gold rush,” or “A flock of paper airplanes flutters through a dense jungle, weaving around trees as if they were migrating birds.” The possibilities are endless. And the outputted videos are downright breathtaking in their clarity, detail, and attention to the prompt.

There’s more, however. Sora is also capable of generating videos based on an image as a prompt. For example, given a DALLE-3 generated image and a text prompt, Sora can animate and bring to life the still image, whether that’s a Shiba Inu wearing a turtleneck or a massive tidal wave crashing into the room. Then, there’s its ability to extend generated videos. Going either forward or backward in time, Sora can start from a segment of a generated video and continue onward, leading to fascinating videos that all start different but lead to the same ending.

A cool quirk of this capability is that the model can be used to create seamless, infinite looping videos, like this one of a mountain biker that never seems to stop flying downhill. But it just continues to get cooler – diffusion models have made possible tons of methods for editing images and videos from text prompts, and by using one such technique, SDEdit, Sora can zero-shot transform the styles and environments of different videos. In one clip, your car is driving down a normal mountain road; in the next, a snow-covered winter landscape; the next, a medieval carriage-ride instead of a sports car.
One of the most mind-bending abilities of Sora is its knack for connecting videos, “creating seamless transitions between videos with entirely different subjects and scene compositions.” Whether it’s moving flawlessly from a mid-motion shot of a drone flying through the air into an underwater environment, or a breathtaking mixture between two different animals, or even a seaside town that transitions almost imperceptibly into a winter wonderland, Sora excels beyond comprehension.

You’d be forgiven if you thought that was all. Like its older sibling DALLE-3, Sora is capable of image generation, too. At up to 2048x2048 resolution, the results are striking. But now we can turn to some of the other, more unexpected, and frankly baffling, capabilities of Sora’s text-to-video model. OpenAI themselves describe these features as “interesting emergent capabilities” that appear when trained Sora is trained at scale.
Maybe most surprising is the 3D consistency of the scenes it generates. With dynamic camera motion, people and scene elements move consistently through three-dimensional space, eerily similar to it having a “world model” it’s making use of. This includes Sora’s uncanny talent – great, but not perfect – for keeping track of details both in the near term and over longer periods. This means it can remember and consistently depict people, animals, and objects even when they are not visible for a while or move out of the scene. To put it differently, Sora has a sense of object permanence. It can also show the same character in different parts of the video while keeping their look the same throughout.
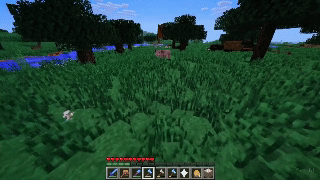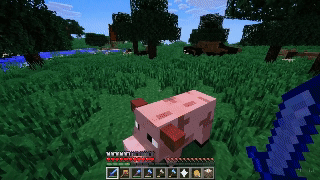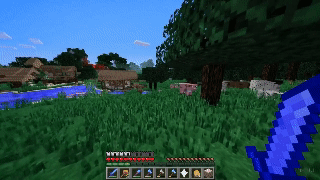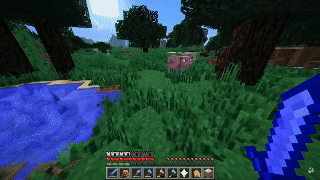
If that wasn’t enough, Sora can even simulate digital worlds. Its zero-shot outputs for “Minecraft gameplay” are particularly impressive, given that it can simultaneously “control the player” while also rendering the simulated world around it in high fidelity. All of these examples and more have slowly unlocked a frenzy of excitement and amazement amongst the tech community. But the biggest question on everyone’s minds seems to be the same: how the hell did OpenAI manage to do this? How does Sora work?
That’s been the burning question on social media in the days since release. Clearly, Sora is a step ahead of the rest of the burgeoning text-to-video models. But unfortunately, OpenAI only tells us so much in their technical report – the rest is just informed guesswork. So what can we say for certain? As OpenAI describes it, “Sora is a generalist model of visual data—it can generate videos and images spanning diverse durations, aspect ratios and resolutions, up to a full minute of high definition video.”

And so, at its core, we know that Sora is a diffusion model with a Vision Transformer (ViT) backbone. It leverages "visual patches" the same way an LLM makes use of “tokens.” This approach allows for the scalable training of the model on internet-scale visual data, enabling it to generate content that spans across different visual domains. OpenAI tells us that they trained a “video compression network” to reduce video data into a compressed latent space, which Sora was trained on and subsequently generates videos within. Then, “given input noisy patches (and conditioning information like text prompts), it’s trained to predict the original ‘clean’ patches.”
Part of the beauty of the model architecture is that Sora can then output different durations, resolutions, aspect ratios for its videos. This lets it create content for different devices directly at their native aspect ratios and allows for improved framing and composition.
Unfortunately, until OpenAI decides to be more open, that’s all we know. But the rumor mill is already up and running with plenty of thoughts about how they might have pulled this off. Many people have already pointed out Sora’s aptitude for modeling physics, leading to the belief that OpenAI must have generated a great deal of training data using a graphics engine like Unreal Engine 5. Others suggest that “Sora's soft physics simulation is an emergent property as you scale up text2video training massively.”
It’s almost certain that a sort of function call to an external physics engine during inference is not what’s taking place. But it begs the question of how Sora’s creations are so temporally and spatially coherent? Does it have an internal model of physics, or a ‘world model,’ of sorts? In the end, we simply don’t know.
What is certain is that we all cannot wait to get our hands on Sora. The early creations being generated are nothing short of remarkable. And it’s quickly becoming clear how much of a game-changer this model will be. So, given everything, can we say yet what Ilya saw? Not yet. But it may just be that all these months ago, Ilya looked into the depths of OpenAI’s new text-to-video model in the works – and something blinked back at him.